
過去にPythonでの機械学習の入門として、簡単な予測をしてみました。

ただ実際にお仕事として使うときには、予測だけではなく、データ同士がどのくらい影響し合っているかまで分析をする必要があります。
今回は少し発展して、データの予測に加えて、データ同士の関連性がどのくらいあるかどうかまで求めてみます♪

使うもの
Google Colabのみ!
Googlecolabを使用し、コード入力
①まずはデータセットをダウンロード
データが揃っていない場合は揃えるところから始めますが、
今回用いるデータセットは既に成形されているものなので、そのままダウンロードします。
#Scikit Learn ->http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html#sklearn.datasets.load_breast_cancer
#乳がんデータ(Breast cancer wisconsin dataset)
import pandas as pd
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
print(data.feature_names)②表形式に変換
names=pd.DataFrame(data=data.data,columns=data.feature_names)
names.head(3)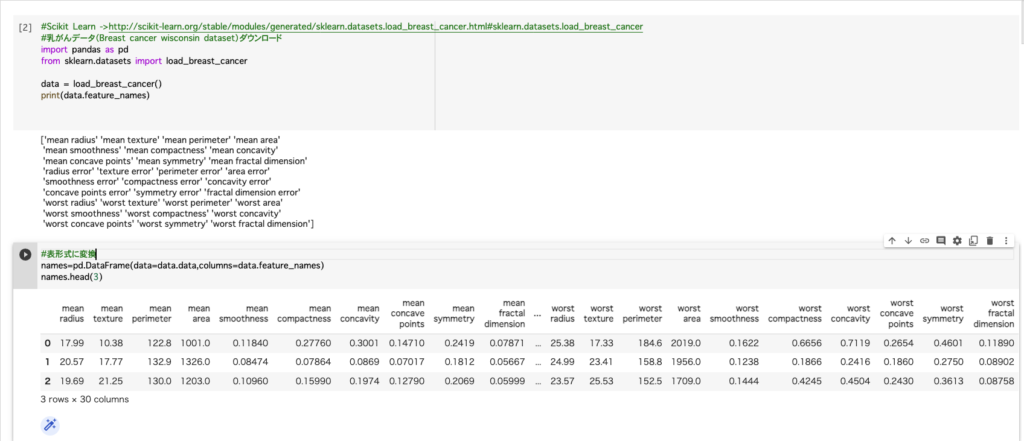
データセットのそれぞれの意味を解説していきます
radius :半径 texture:テクスチャ perimeter:周囲 area:面積 smoothness:滑らかさ
compactness:コンパクトさ concavity:凹み concave points:凹点
symmetry:対称性 fractal dimension:フラクタル次元
mean:平均値 error:標準誤差 worst:1番悪い値(最悪値)
mean areaであれば、腫瘍の平均面積という意味になります。
③データに欠損値がないか確認
names.isnull().any(axis = 0)
全部False・・・今回欠損値はありませんでした😭
④グラフ化
分析の方法がいろいろあるため、調査したい概要によって使い分けていきます。
今回は、項目同士に関連性があるのか、そしてどのくらい強い関連性があるかどうかを見ていきたいと思います。
例えば、腫瘍の滑らかさ(mean smoothness)が悪ければ悪いほど、腫瘍の面積(worst area)も大きくなっていくという関連性が見つけられた場合、
事前にわかっているmean smoothnessの値から最大腫瘍面積を予測することができます。
一方で、腫瘍の対称性(mean symmetry)と腫瘍の最大面積(worst area)の関連性が認められなかった場合、
予後を考える際に見るポイントは、腫瘍の対称性よりも滑らかさということになるのではないかと考えました。
(解釈間違っていたらすみません・・・ご指摘ください)
平均半径と最大腫瘍面積の関連性を見てみます。
%matplotlib inline
names.plot(kind = 'scatter',x = 'mean radius',y= 'worst area')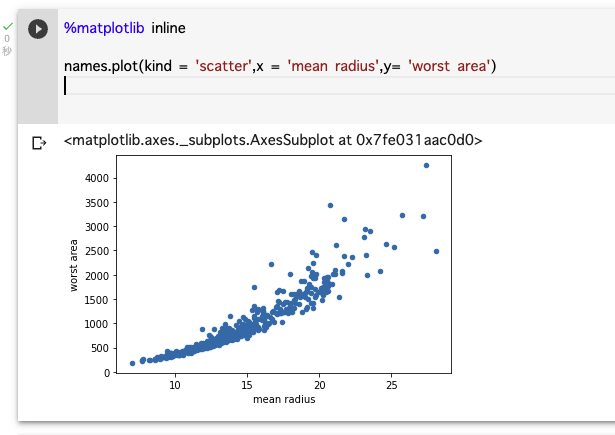
きれいに右肩上がりのため、平均半径と最大腫瘍面積の関連性はあると言える。
ただ、半径が大きくなったら面積も大きくなるので、当たり前と言えば当たり前かもしれない・・
⑤他の項目もグラフ化
今回、最大腫瘍面積と他の項目との関連性を見たいため、全てY軸にはworst areaを置きました。
names.plot(kind = 'scatter',x = 'mean texture',y= 'worst area')
names.plot(kind = 'scatter',x = 'mean perimeter',y= 'worst area')
names.plot(kind = 'scatter',x = 'mean area',y= 'worst area')
names.plot(kind = 'scatter',x = 'mean smoothness',y= 'worst area')
names.plot(kind = 'scatter',x = 'mean compactness',y= 'worst area')
names.plot(kind = 'scatter',x = 'mean concavity',y= 'worst area')
names.plot(kind = 'scatter',x = 'mean concave points',y= 'worst area')
names.plot(kind = 'scatter',x = 'mean symmetry',y= 'worst area')
names.plot(kind = 'scatter',x = 'mean fractal dimension',y= 'worst area')names.plot(kind = 'scatter',x = 'texture error',y= 'worst area')
names.plot(kind = 'scatter',x = 'perimeter error',y= 'worst area')
names.plot(kind = 'scatter',x = 'area error',y= 'worst area')
names.plot(kind = 'scatter',x = 'smoothness error',y= 'worst area')
names.plot(kind = 'scatter',x = 'compactness error',y= 'worst area')
names.plot(kind = 'scatter',x = 'concavity error',y= 'worst area')
names.plot(kind = 'scatter',x = 'concave points error',y= 'worst area')
names.plot(kind = 'scatter',x = 'symmetry error',y= 'worst area')
names.plot(kind = 'scatter',x = 'fractal dimension error',y= 'worst area')names.plot(kind = 'scatter',x = 'worst texture',y= 'worst area')
names.plot(kind = 'scatter',x = 'worst perimeter',y= 'worst area')
names.plot(kind = 'scatter',x = 'worst area',y= 'worst area')
names.plot(kind = 'scatter',x = 'worst smoothness',y= 'worst area')
names.plot(kind = 'scatter',x = 'worst compactness',y= 'worst area')
names.plot(kind = 'scatter',x = 'worst concavity',y= 'worst area')
names.plot(kind = 'scatter',x = 'worst concave points',y= 'worst area')
names.plot(kind = 'scatter',x = 'worst symmetry',y= 'worst area')
names.plot(kind = 'scatter',x = 'worst fractal dimension',y= 'worst area')長いので、画像は割愛
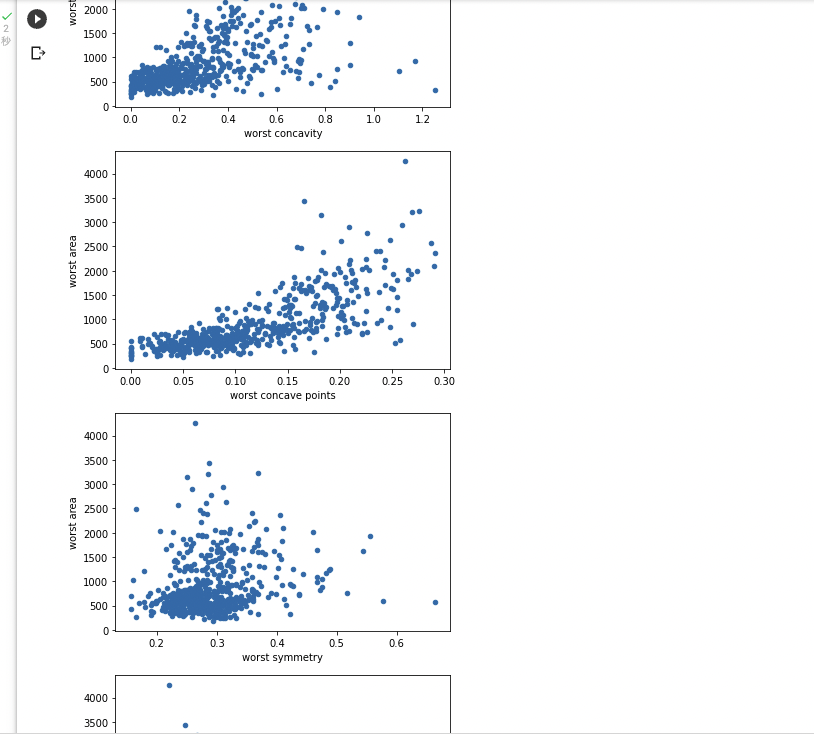
関連性のありそうなものが出揃いました!
mean radius, mean perimeter, mean area, worst perimeter, worst concave points
以上5種類
⑥特徴量と正解データに分割
#特微量の列候補
col = ['mean radius','mean perimeter','mean area','worst perimeter','worst concave points']
x = names[col]
t = names['worst area']
エラーが出なければOK
⑦訓練データとテストデータの分割
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x,t,test_size = 0.2,random_state = 0)
エラーが出なければOK!
⑧重回帰モデルの作成とモデルの学習
LinearRegression関数は重回帰モデルに用いられる。
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train, y_train)
#fitメソッドでモデルに学習させる。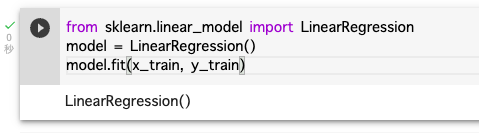
⑨未知データで予測
'mean radius : 20.5
'mean perimeter' : 135
'mean area' : 1400
'worst perimeter' : 145
'worst concave points' : 0.15
の値の患者さんがいたとします。
new = [[20.5,135,1400,145,0.15]]
model.predict(new)
この場合、worst area(最大の腫瘍面積)は1671.44985...という数字になりそうだと予測ができます。
予測ができました!!
⑩モデルの評価
scoreメソッドを活用
model.score(x_test,y_test) #modelのscoreを計算
0.98... 正解率98%っていうことかな?と思いましたが、違いました。
返しているのは決定係数です。
どうやら決定係数は0.8以上だと予測性能が高くて良い計算式と言われるようだったので、
これは予測性能が超高いということになります!
11.MAEを求める
MAE...平均絶対誤差(回帰モデルの予測性能を測る指標)
#平均絶対誤差MAEを計測する
from sklearn.metrics import mean_absolute_error
pred = model.predict(x_test)
mean_absolute_error(y_pred = pred,y_true = y_test)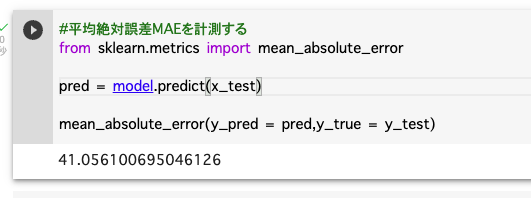
41という数字が出ましたが、面積が1600あたりまで数値が出ることを考えると、誤差は少ない(=予測性能は良い)と考えて良さそうです・・
12.モデルの保存
作ったらモデルの保存は忘れずに!
import pickle
with open('cancer.pkl','wb')as f:
pickle.dump(model,f)13.回帰式による影響度の分析
tmp = pd.DataFrame(model.coef_)
tmp.index = x_train.columns
tmp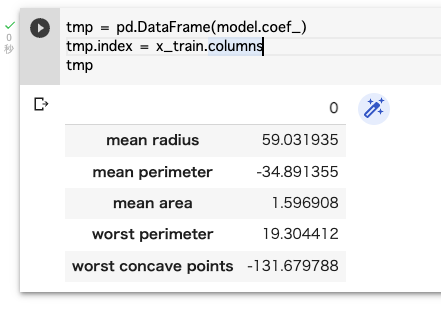
出ている数字の絶対値に着目します。数字が大きいほど、最大腫瘍面積(worst area)に与える影響度は大きいとわかるので、worst concave points(凹点)の影響はかなり大きいと言えます。
今回は、成形されたデータセットを用いて予測・影響度の分析をしました。
次はデータの成形からやってみて、精度を上げていく方法や外れ値の対処法などにも力を入れていきたいなと思います♪
読んでくれてありがとうでした♪