
データベースを作るために最適なPDFファイルを見つけたんだけど、不要な列も入ってしまっていて、、、
それなら、Pandasを用いていらない列を削除して新たに作り替えることができるんだ♪
その方法について説明していくよ

このブログを読むとできるようになること
PDFファイルの表データから必要部分だけを抽出した新たな表データを作成することが可能に
開発環境
Googlecolab
Mac
まずはPDFデータを確認

今回探していた一般名と製品名が対応している表を見つけました。
ただ、枠で囲っている部分のみ欲しく、右の4列は不要です。
成形していきます。
Googlecolabでマウント&必要なパッケージをインストール
マウント
from google.colab import drive
drive.mount('/content/drive')
データ成形するtabulaをインストール
pip install tabula-pyimport pandas as pd
import matplotlib.pyplot as plt
import random
import tabula
tabula.convert_into("/content/drive/MyDrive/pubmed2/ippanmei.pdf", "/content/drive/MyDrive/pubmed2/medilist.csv", stream=True , output_format="csv", pages='all')tabula.conver〜部分で、PDF表を抽出してcsv化しています。
pagesでallと指定したので全てのページのデータを根こそぎ持ってきます。
csv保存したファイルを確認
Pandas構文です
df = pd.read_csv('/content/drive/MyDrive/pubmed2/medilist.csv')
df.head(145)
ちゃんと取れている😀
が、、、なぜか分類4の右列にUnnamedという謎の列が出現(後で消します)
列の名前を変換
df = df.rename(columns={'Unnamed: 0': '一般名'})
df = df.rename(columns={'一般名 商品名': '商品名'})
df.head(3)Unnamed:0→一般名
一般名 商品名→商品名
に直します。
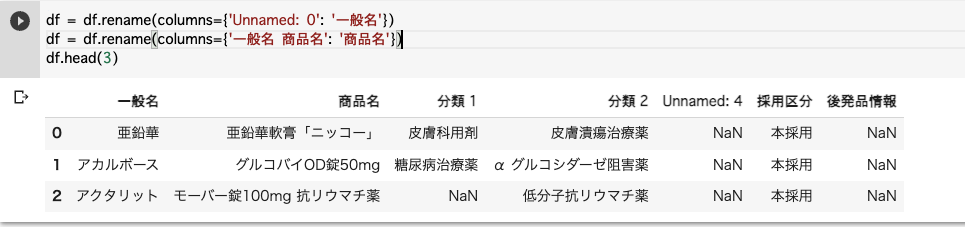
直った!!!
df2 = df2.rename(columns={'分類 2': '大分類'})
df2 = df2.rename(columns={'Unnamed: 4': '空白'})
df2 = df2.rename(columns={'採用区分': '採用'})
df2 = df2.rename(columns={'後発品情報': '後発'})
df2.head(3)数字が列名に入っていた部分については、以前削除する時に手間取ったので全角漢字もしくはひらがなに名前を変更します。
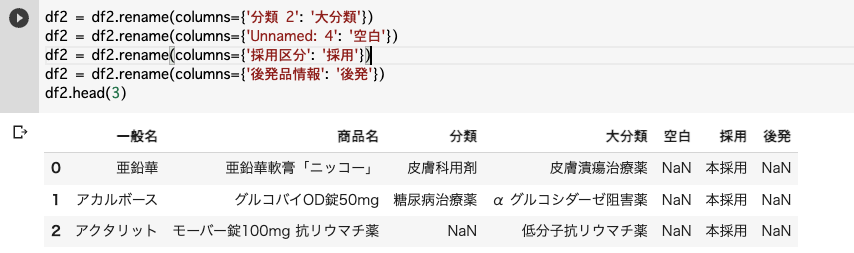
名前も変更できました♪
不要な列を削除
df3 = df2.drop("分類", axis=1)
df3 = df3.drop("大分類", axis=1)
df3 = df3.drop("空白", axis=1)
df3 = df3.drop("採用", axis=1)
df3 = df3.drop("後発", axis=1)
df3.head(3)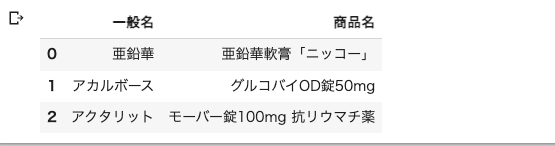
不要な列が削除され、めちゃくちゃ綺麗になった😲
csvとして出力
df3.to_csv('/content/drive/MyDrive/pubmed2/medilist_v2.csv')
出力された!!!🤗
欲しいデータになっているか確認
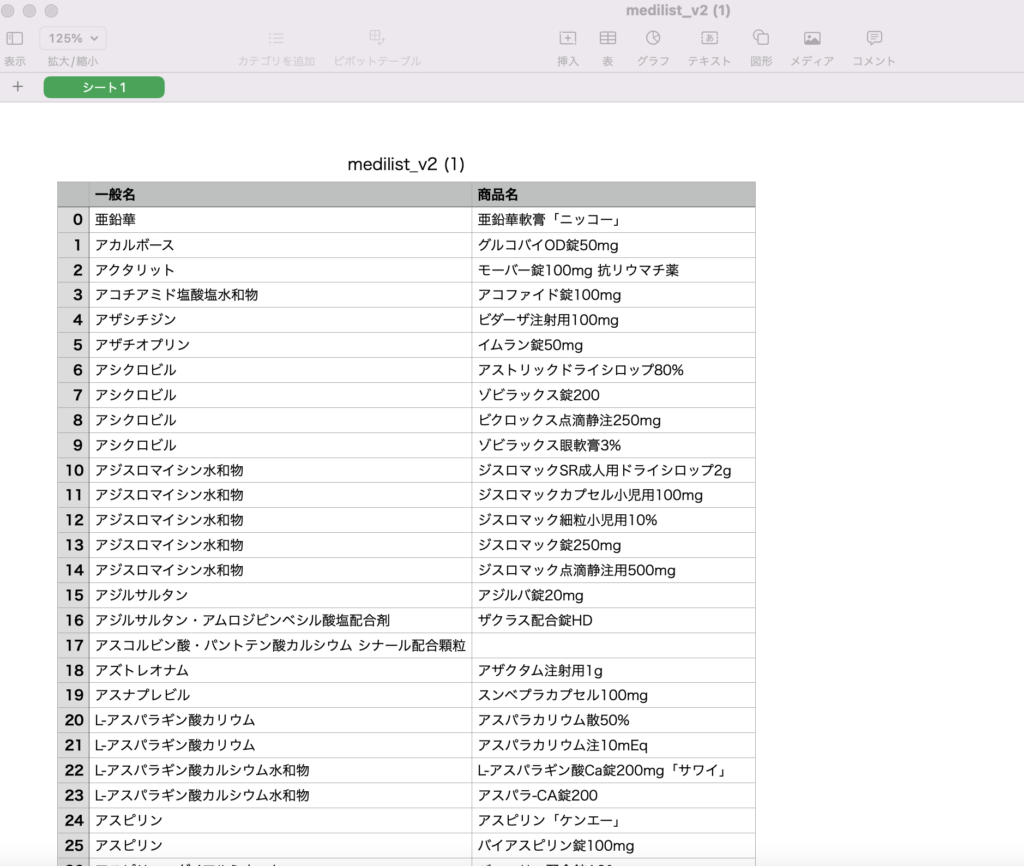
ちゃんとなっている!!!
簡単に不要部分を削除して欲しい形に作り替えることができました。
CSVで今回は試しましたが、もちろんCSV以外でも出力可能です♪
みんなもやってみてね!